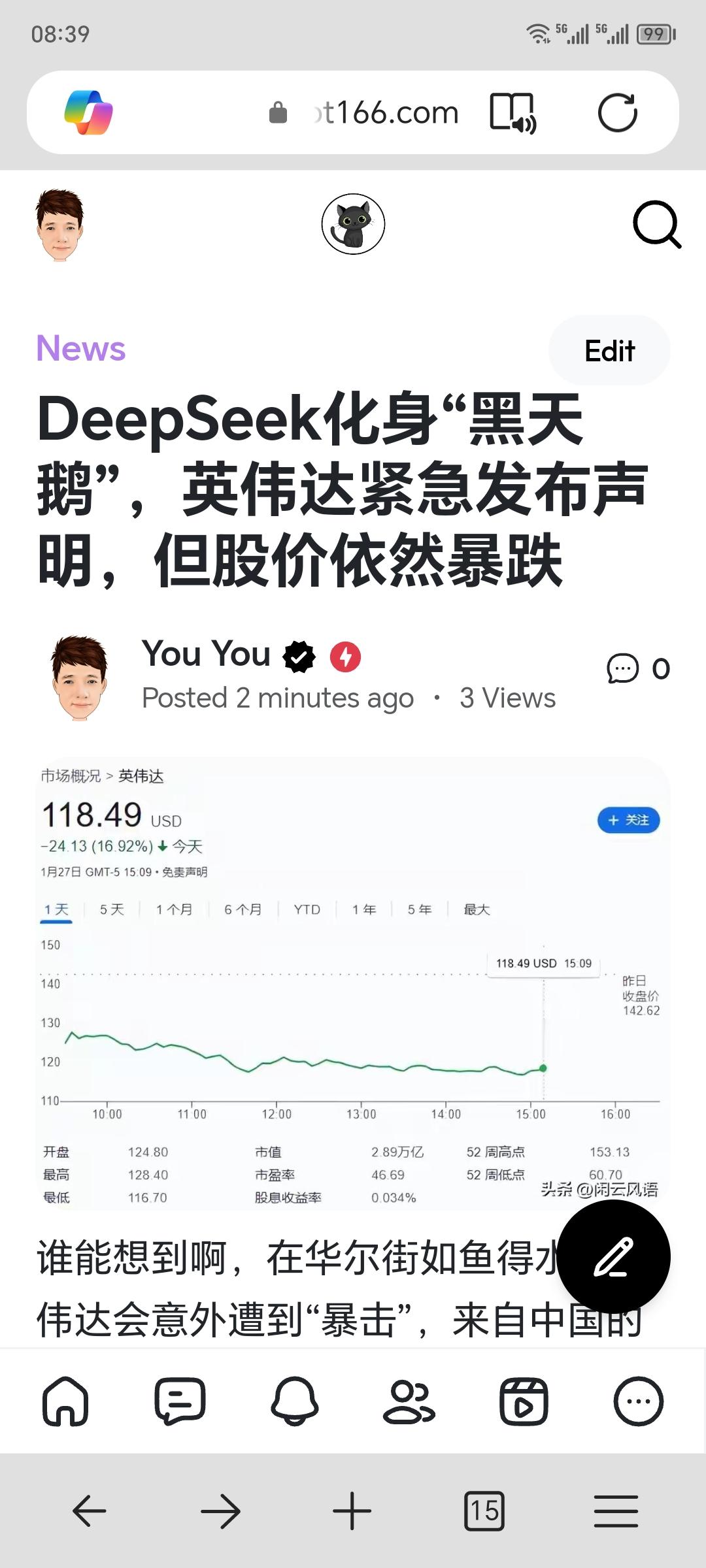
近日,国产大模型DeepSeek在全球AI领域异军突起,其在展现出“史诗级”技术实力的同时也面临外部网络攻击威胁。1月28日,360集团创始人周鸿祎宣布将无偿为DeepSeek提供全方位网络安全防护,“以实际行动践行民族大义,坚决捍卫国产AI技术的尊严与安全”。
近日,国产大模型DeepSeek在全球AI领域异军突起,其在展现出“史诗级”技术实力的同时也面临外部网络攻击威胁。1月28日,360集团创始人周鸿祎宣布将无偿为DeepSeek提供全方位网络安全防护,“以实际行动践行民族大义,坚决捍卫国产AI技术的尊严与安全”。

0 Comments
·0 Shares
·57 Views
·0 Reviews