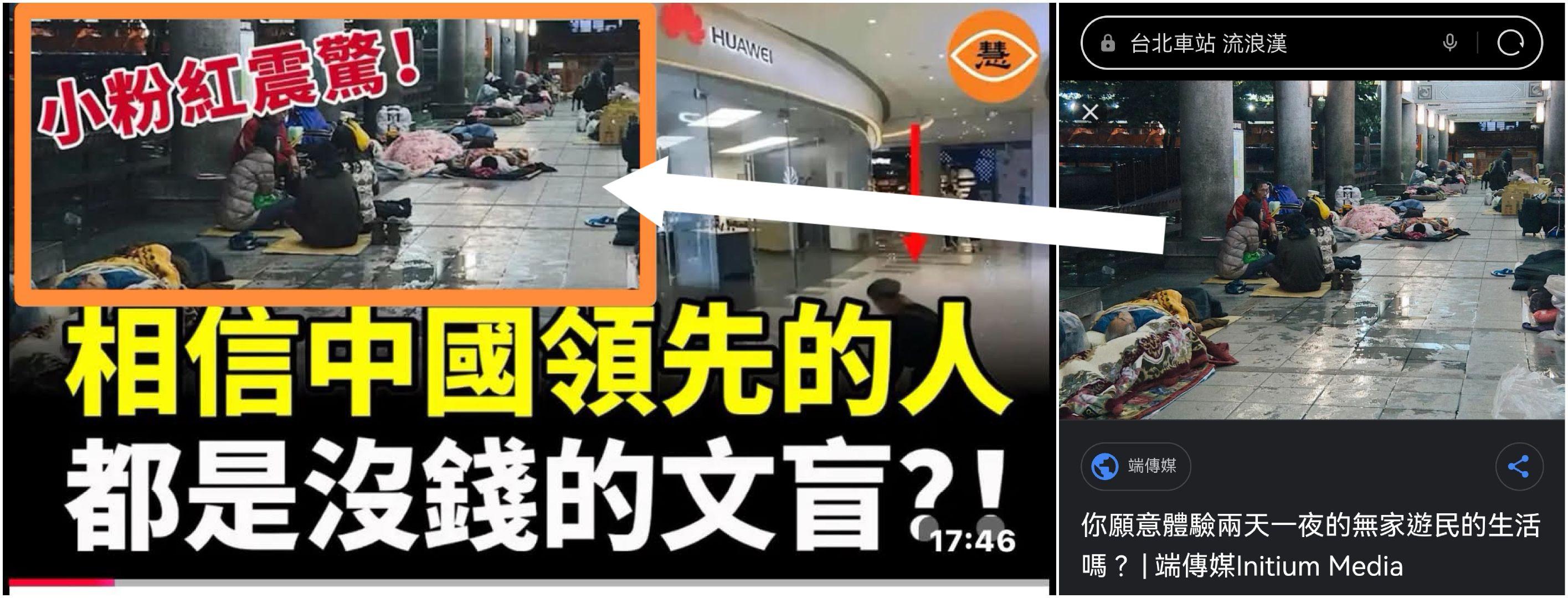
當地時間26日,韓國檢方以涉嫌「內亂頭目」對尹錫悅提起拘留起訴。韓國檢方稱,根據對同案犯案件證據資料的審查結果,決定對尹錫悅提起公訴。
26日早些時候,韓國檢方召開會議,討論被停職總統尹錫悅涉嫌「發動內亂、濫用職權」案的後續處理方案。
#韓國檢方對尹錫悅提起起訴
26日早些時候,韓國檢方召開會議,討論被停職總統尹錫悅涉嫌「發動內亂、濫用職權」案的後續處理方案。
#韓國檢方對尹錫悅提起起訴
當地時間26日,韓國檢方以涉嫌「內亂頭目」對尹錫悅提起拘留起訴。韓國檢方稱,根據對同案犯案件證據資料的審查結果,決定對尹錫悅提起公訴。
26日早些時候,韓國檢方召開會議,討論被停職總統尹錫悅涉嫌「發動內亂、濫用職權」案的後續處理方案。
#韓國檢方對尹錫悅提起起訴